Sebagian besar waktu, ketika Anda perlu memblokir akses SeekportBot atau orang lain crawl bots dengan situs web, alasannya sederhana. Laba-laba web membuat terlalu banyak akses dalam waktu singkat dan meminta sumber daya server web, atau berasal dari mesin pencari di mana Anda tidak ingin situs web Anda diindeks.
Hal ini sangat menguntungkan bagi website yang dikunjungi oleh crawAku menabraknya. Laba-laba web ini dirancang untuk menjelajahi, memproses, dan mengindeks konten halaman web di mesin pencari. Google dan Bing menggunakan crawAku menabraknya. Namun, ada juga mesin pencari yang menggunakan robot untuk mengumpulkan data dari halaman web. Seekport adalah salah satu mesin pencari ini, yang menggunakan crawSeekportBot ler untuk mengindeks halaman web. Sayangnya, terkadang menggunakannya secara berlebihan dan menciptakan lalu lintas yang tidak perlu.
Cuprin
Apa itu SeekportBot?
SeekportBot adalah web crawler dikembangkan oleh perusahaan Seekport, yang berbasis di Jerman (tetapi menggunakan IP dari beberapa negara, termasuk Finlandia). Bot ini digunakan untuk merayapi dan mengindeks situs web sehingga dapat ditampilkan di hasil mesin pencari. Seekport. Mesin pencari non-fungsional, sejauh yang saya tahu. Setidaknya, itu tidak memberikan hasil apa pun untuk saya untuk frase kunci apa pun.
SeekportBot Menggunakan user agent:
"Mozilla/5.0 (compatible; SeekportBot; +https://bot.seekport.com)"Bagaimana memblokir akses ke SeekportBot atau lainnya crawSaya mengklik sebuah situs web
Jika Anda sampai pada kesimpulan bahwa laba-laba web ini atau lainnya, tidak perlu memindai seluruh situs web Anda dan membuat lalu lintas yang tidak perlu ke server web, Anda memiliki beberapa metode yang dapat digunakan untuk memblokir akses mereka.
Firewall di tingkat server web
Mereka adalah aplikasi firewall open-source yang dapat diinstal pada sistem operasi Linux dan dapat dikonfigurasi untuk memblokir lalu lintas berdasarkan beberapa kriteria. Alamat IP, lokasi, port, protokol, atau agen pengguna.
APF (Advanced Policy Firewall) adalah perangkat lunak yang dapat digunakan untuk memblokir bot yang tidak diinginkan, di tingkat server.
Karena SeekportBot dan web spider lainnya menggunakan beberapa blok IP, aturan pemblokiran yang paling efektif didasarkan pada "user agent". Jadi, jika Anda ingin memblokir akses SeekportBot melalui APF, yang harus Anda lakukan adalah terhubung ke server web melalui SSH, dan tambahkan aturan filter di file konfigurasi.
1. Buka file konfigurasi dengan nano (atau penerbit lain).
sudo nano /etc/apf/conf.apf2. Cari baris yang dimulai dengan “IG_TCP_CPORTS” dan tambahkan agen pengguna yang ingin Anda blokir di akhir baris ini, diikuti dengan koma. Misalnya, jika Anda ingin memblokir user agent "SeekportBot", barisnya akan terlihat seperti ini:
IG_TCP_CPORTS="80,443,22" && IG_TCP_CPORTS="$IG_TCP_CPORTS,SeekportBot"3. Simpan file dan restart layanan APF.
sudo systemctl restart apf.serviceAkses "SeekportBot" akan diblokir.
Saring web crawls dengan bantuan Cloudflare – Blokir akses SeekportBot
Dengan bantuan Cloudflare, menurut saya metode teraman dan ternyaman untuk membatasi akses beberapa bot ke situs web dengan berbagai cara. Metode yang juga saya gunakan dalam kasus ini SeekportBot untuk memfilter lalu lintas ke toko online.
Dengan asumsi bahwa Anda telah menambahkan situs web ke Cloudflare dan layanan DNS diaktifkan (yaitu, lalu lintas ke situs web melewati Cloudflare), ikuti langkah-langkah di bawah ini:
1. Buka akun Clouflare Anda dan buka situs web yang ingin Anda batasi aksesnya.
2. Pergi ke: Security → WAF dan menambahkan aturan baru. Create rule.
3. Pilih nama untuk aturan baru, Field: User Agent - Operator: Contains - Value: SeekportBot (atau nama bot lainnya) – Choose action: Block - Deploy.
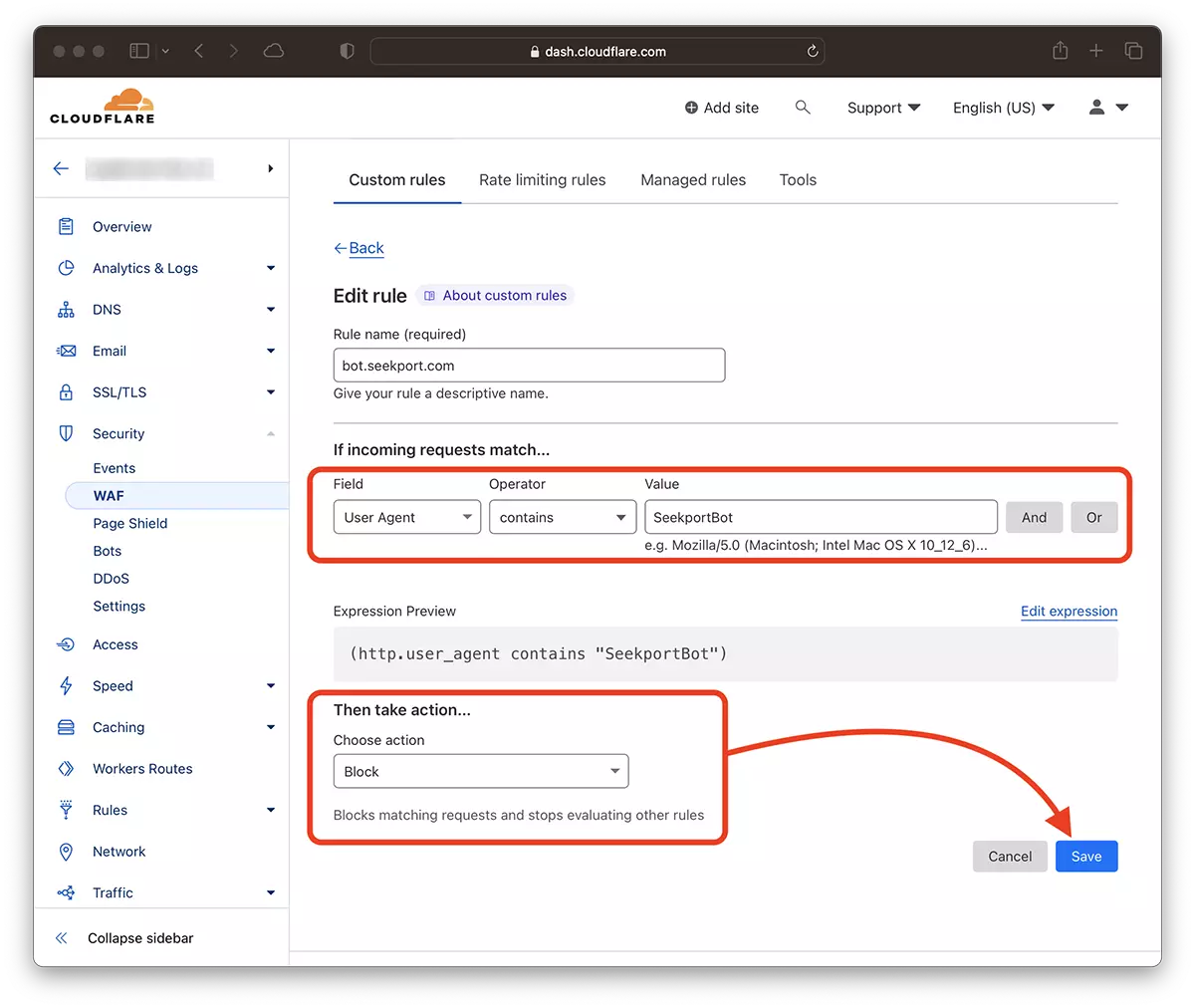
Hanya dalam beberapa detik, aturan baru WAF (Web Application Firewall) itu mulai berlaku.
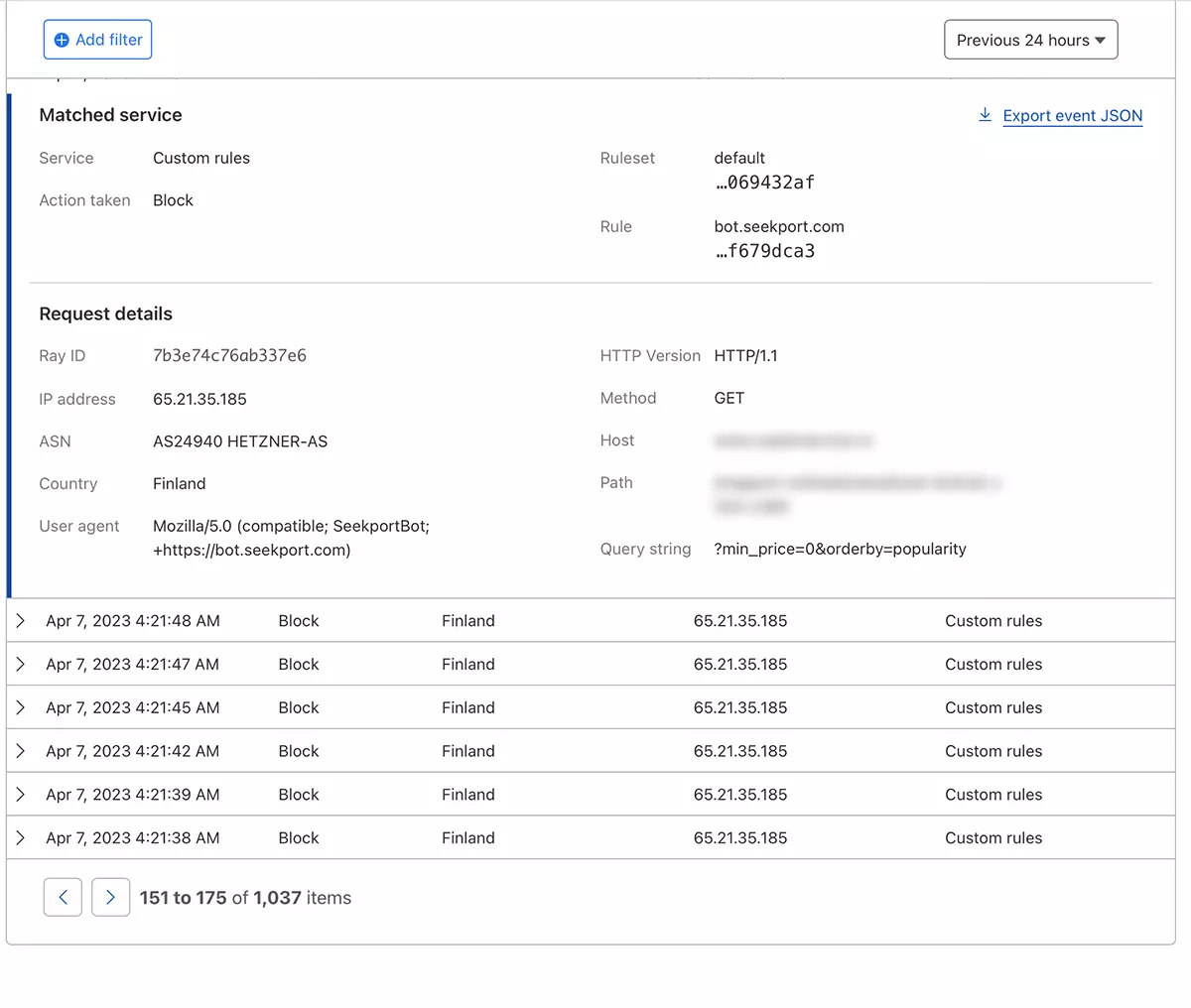
Secara teori, frekuensi laba-laba web mengakses suatu situs dapat diatur robots.txt, tapi... itu hanya teori.
User-agent: SeekportBot
Crawl-delay: 4Banyak web crawlerii (kecuali Bing dan Google) tidak mengikuti aturan ini.
Kesimpulannya, jika Anda mengidentifikasi web crawSaya yang mengakses situs Anda secara berlebihan, yang terbaik adalah memblokir aksesnya sepenuhnya. Tentu saja, jika bot ini bukan dari mesin pencari yang Anda minati.